CS224N 강의 자료중 Natural Language Processing의 Note 전반을 개인적으로 필요한 부분만 정리한 글입니다.
CBOW - Continuous Bag of Words Model
Skip - Gram
Negative Sampling
Hierarchinal Softmax
CBOW - Continuous Bag of Words Model
Predicting a center word from the surrounding context
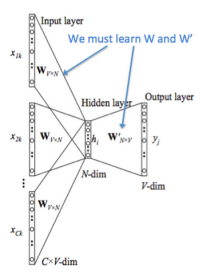
주변 문맥으로 중심 단어 예측 - v: (input vector) when the word is in the context =입력 벡터, 문맥에 있는 단어 - u: (output vector) when the word is in the center =출력 벡터, 중앙에 있는 단어 - w_i : Word i from vocabulary V =어휘 속 단어 i - V ∈ R^(n×|V|) : Input word matrix = 입력 단어 매트릭 - vi : i-th column of V, the input vector representation of word wi = V의 i 번째 열 , wi 의 입력 백터 표현 - U ∈ R^(|V|×n) : Output word matrix = 출력 단어 매트릭 - ui : i-th row of U, the output vector representation of word wi = U의 i번째 행 , wi의 출력 벡터 표현
위 모델의 작동 방식 1. 입력 문맥 사이즈에 맞게 한개의 핫워드 벡터 생성 m : (x^(c−m) , . . . , x ^(c−1) , x ^(c+1) , . . . , x ^(c+m) ∈ R^|V| ). 2. 문맥에 맞는 임베디드 월드 벡터를 얻는다. (vc−m = Vx ^(c−m) , vc−m+1 = Vx^(c−m+1) , . . ., vc+m = Vx^(c+m) ∈ Rn ) 3. 벡터를 평균화 4. 스코어 벡터 생성 z = Uvˆ ∈ R^|V| 유사한 벡터의 내적이 더 크고, 높은 점수를 위해 값을 밀착 시킴 5. 점수를 확률로 변환 yˆ = softmax(z) ∈ R^|V| 6. 생성된 확률을 실제 확률과 일치 시키고, yˆ ∈ R^|V| => y ∈ R^|V| 하나의 핫백터가 된다.
최종적으로 구한 값을 통하여, 교차 엔트로피을 통하여 아래와 같이 구한다.
y를 원핫 벡터로 단순화 하면 다음과 같다. H(yˆ, y) = −yi log(yˆi)
예측이 완벽할 경우 H(yˆ, y) = −1 log(1) = 0
예측이 매우 안좋을 경우 H(yˆ, y) = −1 log(0.01) ≈ 4.605.
아래와 같이 최소합니다.
이후 Stochastic gradient descent (SGD)를 사용하여 계속 업데이트 보정한다. Unew ← Uold − α∇U J Vold ← Vold − α∇V J